일단 도게자 박고 시작하겠습니다.
초심을 잃은 것이 아니라.. 연초라 회사 프로젝트가 하나 둘 시작되고 있네요.
업무랑 블로그를 병행하는 것이 정말 보통이 아니구나를 느끼고 있습니다.
https://ddalgakdesign.tistory.com/15
Midjourney 딸깍 활용하기 (3) 스타일 레퍼런스 --sref
저번 글(파라미터 Parameter를 활용하기)에서 이어집니다!https://ddalgakdesign.tistory.com/14 Midjourney 딸깍 활용하기 (2) 파라미터 Parameter파라미터 Parameter를 잘 활용하는 방법지난 글에 이어서, 오늘은 미
ddalgakdesign.tistory.com
이전 글에서 이어집니다.
캐릭터 레퍼런스의 활용
스타일 레퍼런스를 어떻게 활용하는 지를 배웠으니, 오늘은 캐릭터 레퍼런스를 활용하는 방법을 배워보도록 하겠습니다.
사실 굉장히 간단한 파라미터라 스타일 레퍼런스와 같이 소개드릴까 고민했었는데요.
쉽게 말해서 내가 생성하고자 하는 '캐릭터'의 특징을 유지하는 파라미터입니다.

기본적인 사용은 --cref (캐릭터 이미지의 주소) --cw(0~100)를 프롬프트 뒤에 붙여주면 됩니다.
자, 예시와 함께 보면서 설명드리도록 하겠습니다.
아래 캐릭터를 먼저 생성하였습니다.
빨간 곱슬머리에 황금빛 수염을 가지고 있는 백인 남성입니다.

위의 캐릭터의 특징을 유지하며 이미지를 생성해 보도록 하겠습니다.
일단 해당 이미지를 디스코드에 업로드해줍니다.
그리고 생성하고 싶은 이미지의 프롬프트 뒤에 해당 주소를 --cref --cw 사이에 입력해 주도록 하겠습니다.
먼저, 캐릭터 레퍼런스를 사용하지 않은 이미지입니다.
Prompt : A man left alone in the mars, extreme close up shot, lonely but with confident. his face is reflect in the helmet.

이제 캐릭터 레퍼런스를 사용하여 다시 생성해 보도록 하겠습니다.
Prompt : A man left alone in the mars, extreme close up shot, lonely but with confident. his face is reflect in the helmet. --cref (이미지 주소) --cw 50

보시는 바와 같이, 기존 캐릭터의 외형 특징을 유지하면서 이미지가 생성된 것을 확인할 수 있습니다.
이제 --cref 사용법은 이해하셨을 텐데요. 그럼 --cw는 무엇일까요?
--cw는 기존 스타일 레퍼런스와 같이 'character weight'의 약자입니다.
즉, 캐릭터의 외형 특징을 얼마나 유지할지를 결정하는 파라미터라고 보시면 됩니다.
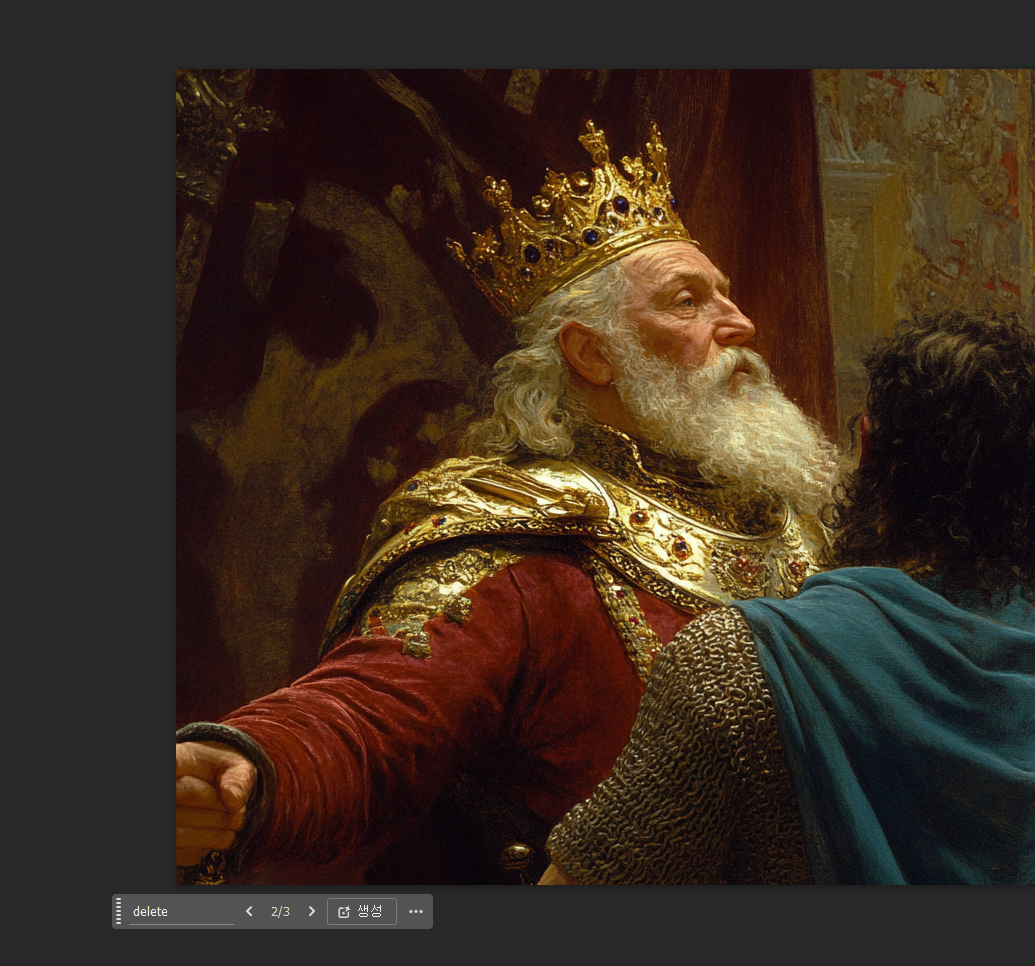
기본은 100이고, 0에 가까워질수록 얼굴을 제외한 헤어스타일, 패션이 달라집니다.
아래 이미지를 참고하시면 되겠습니다.


웹 플랫폼에서의 캐릭터 레퍼런스의 활용
저번 스타일 레퍼런스도 그렇고, 이러한 참고 이미지의 활용은 Midjourney 자체 웹 플랫폼이 훨씬 편리한데요.
웹에서 캐릭터 레퍼런스를 어떻게 활용하는지 알아보도록 하겠습니다.
방법은 놀라울 정도로 간단한데요.

쓰고자 하는 캐릭터를 생성하고, 이를 상단 채팅창에 드래그&드롭해줍니다.

첨부된 이미지 위에 커서를 가져가면 3개의 옵션이 나타나게 되는데요.
왼쪽부터 차례대로
1. 캐릭터 레퍼런스
2. 스타일 레퍼런스
3. 이미지 프롬프트
로 사용할 수 있습니다.
그럼 이제 제일 좌측의 캐릭터 레퍼런스를 눌러주고 Create를 해보도록 하겠습니다.

해당 레퍼런스 캐릭터를 유지하며 이미지가 생성된 것을 확인하실 수 있습니다.
이를 다시 사용하시려면 오른쪽의 섬네일 이미지를 클릭하기만 하면 됩니다.
실제 사람의 얼굴로도 사용이 가능할까요?
이 부분에 대해서는 저도 의문인데요. 어떠한 사람의 외형을 최대한 닮게 만들려면
8장 정도를 캐릭터 레퍼런스로 사용하여 제작하면 된다는 소문이 있었습니다.
다만 제 사진을 넣어봤을 때 그다지 닮게 나오진 않았습니다. Midjourney가 실제 사람의 사진은 사회적인 이슈로
알아서 거르는(?) 것일 수도 있는 것 같습니다.
그럼 오늘은 캐릭터 레퍼런스에 대해 알아보았습니다.
다음에는 '미드저니스러운 이미지'를 피하는 방법에 대해 알아보도록 하겠습니다.
'딸깍 AI 디자인 툴 공부 > Midjourney' 카테고리의 다른 글
| Midjourney 딸깍 활용하기 tip. 유용한 프롬프트 (2) Shot (0) | 2025.01.25 |
|---|---|
| Midjourney 딸깍 활용하기 tip. 유용한 프롬프트 (1) Angle (2) | 2025.01.18 |
| Midjourney 딸깍 활용하기 (3) 스타일 레퍼런스 --sref (2) | 2024.12.30 |
| Midjourney 딸깍 활용하기 (2) 파라미터 Parameter (1) | 2024.12.30 |
| Midjourney 딸깍 활용하기 (1) 인터페이스 (4) | 2024.12.04 |